
오늘은 몰랐으면 내일은 알면 된다
2022-11-09 (2) 서브쿼리 Subquery 본문
SELECT employee_id, MAX(salary)
FROM employees;위의 max는 모든 행을 탐색하고 난 다음에 최대값을 결정하는데, 최대값이 결정될 때에는 employee_id가 없기 때문에 논리적 위배로 오류가 발생한다.
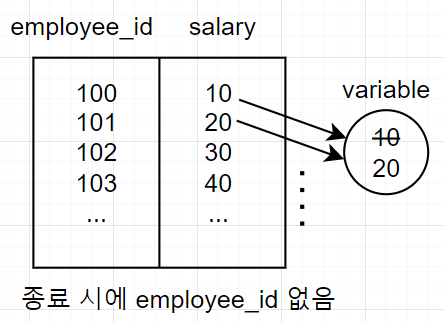
위의 SQL문은 다음의 과정을 거친다.
1) 최대급여를 계산한다.
SELECT MAX(salary) FROM employees
2) 최대급여와 같은 급여를 받는 사원을 다시 행을 탐색하며 검색한다.
SELECT employee_id, salary FROM employees WHERE salary = 1) 에서 나온 값
이 둘을 합칠수도 있지 않을까?
SELECT employee_id, salary FROM employees WHERE salary = (SELECT MAX(salary) FROM employees)
위와 같이 표현하는 것이 서브쿼리이다.
[서브쿼리의 특징]
| 1. 서브쿼리는 연산자와 같은 비교 또는 조회의 대상의 오른쪽에 놓이며, ( ) 로 묶어서 사용한다. |
| 2. ORDER BY 절을 사용할 수 없다. |
| 3. 서브쿼리의 SELECT 절에 명시한 열은 메인쿼리의 비교 대상과 같은 자료형과 같은 개수로 지정해야 한다. |
| 4. 서브쿼리의 SELECT 문의 결과 행 수는 메인쿼리의 연산자 종류와 호환 가능해야 한다. 즉 메인쿼리에 사용한 연산자가 단 하나의 데이터로만 연산이 가능한 연산자라면, 서브쿼리의 결과 행 수는 반드시 하나여야 한다. |
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id;반면 위의 경우, map의 형태로 department_id라는 key 값과, max값이 될 value 페어가 생긴다. 이후 행을 탐색하면서 해당 키를 찾아서 더 큰값인 경우에는 value를 교체한다. key가 없는 경우에는 또 새로운 페어를 만든다.
탐색이 끝나면 생성된 map을 바탕으로 결과값을 반환한다.
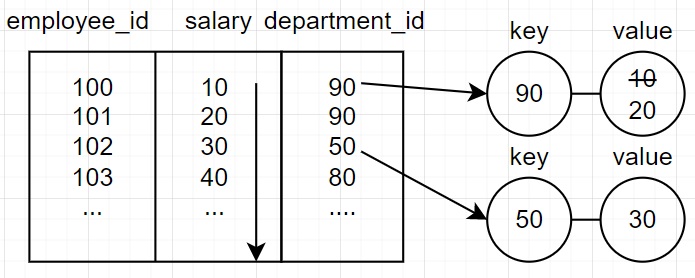
예제) 부서별 부서번호, 최대급여, 최대급여자 사번을 출력하시오.
1) 부서별 부서번호, 최대급여를 계산한다.
2) 1)의 부서번호와 부서번호가 같고, 1)의 최대급여와 같은 급여를 받는 사원을 검색한다.
단순히 생각하면 이렇게 하면 될 것 같다.
SELECT department_id, salary, employee_id
FROM employees
WHERE department_id, salary = (SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id);그러나 이 SQL문은 오류가 나는데, 서브쿼리가 여러행을 반환하는 다중행서브쿼리일 경우 메인쿼리와 일반 비교 연산자(=, <>, >, >=, <, <=)를 사용할 수 없기 때문이다.
메인쿼리와 비교하기 위해서는 특수비교연산자를 사용해야 한다.(IN, ANY>, ANY<, ALL>, ALL<)
따라서 다음과 같이 변경하여 사용해야 한다.
SELECT department_id, salary, employee_id
FROM employees
WHERE (department_id, salary) IN (SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id);| ANY> | 최소값보다 크다 |
| ANY< | 최대값보다 작다 |
| ANY= | IN |
| ALL> | 최대값보다 크다 |
| ALL< | 최소값보다 작다 |
단일행 서브쿼리: 메인쿼리와 일반비교연산자 사용
다중행 서브쿼리: 메인쿼리와 특수비교연산자 사용(IN, ANY, ALL)
- 서브쿼리 위치에 따른 명칭 -
스칼라 쿼리 : SELECT
인라인뷰 : FROM
서브쿼리 : WHERE
[인라인뷰 inline view]
: FROM절에서 사용하는 서브쿼리를 의미한다.

참고) rownum 의사컬럼 : 행번호를 가지는 수도컬럼(의사 컬럼: 테이블에 있는 일반 컬럼처럼 행동하지만 실제로 테이블에 저장되어있지는 않음), having 이 끝나고 select를 할 때 조건을 만족하는 행을 찾으면 1씩 증가한다.
SELECT rownum, employee_id, salary
FROM employees
ORDER BY salary DESC;
rownum이 엉망인 이유는 이미 SELECT 까지의 과정을 거치면서 rownum은 발급되었고, 그 다음에 order by를 실행했기 때문이다.
rownum까지 정렬을 해주려면 다음과 같이 쿼리를 바꿔준다. 즉, 내림차순 정렬한 결과에 새롭게 rownum을 1부터 매긴다.
SELECT rownum, employee_id, salary
FROM (SELECT employee_id, salary FROM employees ORDER BY salary DESC);
만약, 급여가 많은 사원부터 10명을 출력하려면 아래와 같이 where 조건을 추가한다.
SELECT rownum, employee_id, salary
FROM (SELECT employee_id, salary FROM employees ORDER BY salary DESC)
WHERE rownum <= 10;
그러면 5위부터 10위까지를 뽑으려면 다음과 같이 하면 될까?
SELECT rownum, employee_id, salary
FROM (SELECT employee_id, salary FROM employees ORDER BY salary DESC)
WHERE rownum between 5 and 10;위의 쿼리를 실행하면 아무런 결과가 나오지 않는다. 서브쿼리가 끝나면 rownum도 함께 끝나게 되기 때문이다.
서브쿼리가 끝나고 메인쿼리로 오면 rownum이 다시 1부터 매겨진다.
그런데, 현재 메인쿼리의 rownum은 1로 다시 돌아왔음에도 조건은 rownum이 5와 10 사이에 있는거냐고 묻고있다.
따라서 조건에 맞지 않으니 SELECT에 걸리지 않고, 걸리지 않았으니 rownum이 증가하지 않아서 여전히 1인데 커서만 다음행으로 넘어가는 꼴이 된다. 영원히 SELECT 에 걸리는 행은 없다.
그럼 어떻게 해야하나? 서브쿼리에서 사용한 rownum에 아래와 같이 별칭을 준다.
select rn, rownum, employee_id, salary
from (select rownum rn, employee_id, salary
from (select employee_id, salary
from employees
order by salary desc
)
) where rn between 5 and 10;그러면 다음과 같이 서브쿼리에서 매겨진 rownum을 그대로 사용할 수 있게 된다.

왜 이런짓을 하는걸까? 페이징에서 이 원리를 사용하게 된다.
예를들어 1000건의 자료가 있고 한 페이지에 10건씩 보여주겠다고 해보자.
DB에서 1000개를 다 들고와서 프로그램쪽에서 잘라서 쓰는 것과 특정 페이지 요청시 해당 페이지에 해당하는 10건만 DB에서 받아와서 뿌리는 것과 어느것이 더 퍼포먼스가 좋을까?
당연히 후자일 것이다. 그리고 당연히 페이징시에는 그렇게 처리해야 한다. 지금에야 전체 자료가 1000건이지만 1억건이면 어떡할건가?
한 페이지에 10건을 보여주겠다면, 아래와 같이 rn 값만 조정하면 된다.
select rn, rownum, employee_id, salary
from (select rownum rn, employee_id, salary
from (select employee_id, salary
from employees
order by salary desc
)
) where rn between 1 and 10;2페이지의 데이터는 다음과 같이 조정하면 된다.
select rn, rownum, employee_id, salary
from (select rownum rn, employee_id, salary
from (select employee_id, salary
from employees
order by salary desc
)
) where rn between 11 and 20;위의 쿼리를 해석하자면, 급여를 가지고 내림차순 정렬한 결과에 행번호를 1부터 매기고, 그 매긴 값을 기준으로 11과 20사이에 있는 데이터를 출력하라는 뜻이다.
[스칼라 쿼리 scalar subquery]
: SELECT절에 하나의 열 영역으로서 결과를 출력할 수 있다.
그러나 여러테이블을 가지고 데이터를 출력해야 한다면 JOIN ON을 쓰자.
'Java > JAVA 개발자 양성과정' 카테고리의 다른 글
| 2022-11-10 (3) 제약 조건 (0) | 2022.11.10 |
|---|---|
| 2022-11-10 (1) 데이터 정의어(DDL: Data Definition Language) (0) | 2022.11.10 |
| 2022-11-09 (1) JOIN (0) | 2022.11.09 |
| 2022-11-08 (5) 다중행 함수, GROUP BY (0) | 2022.11.08 |
| 2022-11-08 (4) 람다식(Lambda Expression) (0) | 2022.11.08 |


